层次分析法
# 层次分析法
评价一个总体目标,使用权重是一个简便易行的方法,即把目标拆分成为几个相互独立的子目标项,根据子目标项的权重,把它的得分乘以它的权重并累加汇总。例如,假设我们要按“德、智、体、美、劳”共5个子目标项来评价一个学生,先把权重分别设定到“德、智、体、美、劳”。这里假设分别是“德=0.2、智=0.2、体=0.2、美=0.2、劳=0.2”,这几项权重的总和等于1。我们也可以把权重理解为子目标项在总体目标饼图中所占的比例。在这个特例中,5个子目标项都认为同等重要,因此它们的权重都等于0.2。设定某个子目标项的权重是重点,上例子中,设定的权重显然太主观和随意,因此,得出的总体目标评价,也不够有说服力。
层次分析法(Analytic Hierarchy Process, AHP)是美国运筹学家 Thomas Saaty (opens new window) 于20世纪70年代初,为美国国防部研究“根据各个工业部门对国家福利的贡献大小而进行电力分配”课题时,应用网络系统理论和多目标综合评价方法,提出的一种层次权重决策分析方法。
层次分析法是一种解决多目标的复杂问题的定性与定量相结合的决策分析方法。该方法将定量分析与定性分析结合起来,用决策者的经验比较两两目标子项之间的相对重要程度,并合理地给出每个目标子项的权重,利用权重求出各方案的优劣次序,能够有效地应用于那些难以用定量方法解决的课题。
# 算法简述
层次分析法算法的基本原理与步骤,此处不赘述,可参考:
其计算过程主要是以下步骤:
- 建立层次结构模型。将总体目标拆分成为相互独立的子目标项(一般不多于9个)。
- 构造判断矩阵(或比较矩阵)。让领域专家对子目标项两两评价,给出比较矩阵。
- 层次单排序及一致性检验。通常用近似算法计算。
- 层次总排序及一致性检验。
其中,一致性检验,是为了校验比较矩阵中,专家给的判断值是否存在不合逻辑的情况。如果一致性校验不通过,则需要检查并修改比较矩阵。
层次分析法有多种语言的算法实现,Python 作为一种常见的数值分析编程语言,在互联网上可以搜索到多个实现:
- 知乎 - 【AHP】层次分析法原理与Python实现 (opens new window)
- 知乎 - 层析分析法AHP原理及Pyhon实现 (opens new window)
- 知乎 - AHP | 层次分析法原理及Python实现 (opens new window)
第三方包,相对成熟些的,有下面两个:
这里推荐使用 AHPy,它的文档看起来更详细和完善些。GitHub 提交更新记录的日期也是最近的。
# 使用场景
下面的几个典型示例,是基于 AHPy 给出的。它展示了层次分析法的常见使用场景。
# 示例1: 美国饮料消费占比
算法作者在2008年的一篇文献 Decision making with the analytic hierarchy process (opens new window) 中,30名参与者被要求比较美国饮料的相对消费量。例如,他们认为咖啡(Coffee)的消费量远高于葡萄酒(Wine),但消费速度与牛奶(Milk)相同。从他们的答案中得出的比较矩阵如下:
| 咖啡 | 葡萄酒 | 茶 | 啤酒 | 苏打水 | 牛奶 | 水 | |
|---|---|---|---|---|---|---|---|
| 咖啡 | 1 | 9 | 5 | 2 | 1 | 1 | 1/2 |
| 葡萄酒 | 1/9 | 1 | 1/3 | 1/9 | 1/9 | 1/9 | 1/9 |
| 茶 | 1/5 | 3 | 1 | 1/3 | 1/4 | 1/3 | 1/9 |
| 啤酒 | 1/2 | 9 | 3 | 1 | 1/2 | 1 | 1/3 |
| 苏打水 | 1 | 9 | 4 | 2 | 1 | 2 | 1/2 |
| 牛奶 | 1 | 9 | 3 | 1 | 1/2 | 1 | 1/3 |
| 水 | 2 | 9 | 9 | 3 | 2 | 3 | 1 |
下表显示了使用 AHP 计算的饮料的相对消费量(鉴于此矩阵)以及从美国统计摘要中获取的饮料的实际相对消费:
| 咖啡 | 葡萄酒 | 茶 | 啤酒 | 苏打水 | 牛奶 | 水 | |
|---|---|---|---|---|---|---|---|
| AHP | 0.177 | 0.019 | 0.042 | 0.116 | 0.190 | 0.129 | 0.327 |
| 实际统计数据 | 0.180 | 0.010 | 0.040 | 0.120 | 0.180 | 0.140 | 0.330 |
我们可以看到数据非常相近。从另一个方面来说,30人的数据样本能够如此精确地靠近总体统计数据,从性价比上说是非常高的。
基于 AHPy,它的实现代码如下:
>>> import ahpy
>>> drink_comparisons = {('coffee', 'wine'): 9, ('coffee', 'tea'): 5,
('coffee', 'beer'): 2, ('coffee', 'soda'): 1,
('coffee', 'milk'): 1, ('coffee', 'water'): 1 / 2,
('wine', 'tea'): 1 / 3, ('wine', 'beer'): 1 / 9,
('wine', 'soda'): 1 / 9, ('wine', 'milk'): 1 / 9,
('wine', 'water'): 1 / 9, ('tea', 'beer'): 1 / 3,
('tea', 'soda'): 1 / 4, ('tea', 'milk'): 1 / 3,
('tea', 'water'): 1 / 9, ('beer', 'soda'): 1 / 2,
('beer', 'milk'): 1, ('beer', 'water'): 1 / 3,
('soda', 'milk'): 2, ('soda', 'water'): 1 / 2,
('milk', 'water'): 1 / 3}
>>> drinks = ahpy.Compare(name='Drinks', comparisons=drink_comparisons, precision=3, random_index='saaty')
>>> print(drinks.target_weights)
{'water': 0.327, 'soda': 0.19, 'coffee': 0.177, 'milk': 0.129, 'beer': 0.116, 'tea': 0.042, 'wine': 0.019}
>>> print(drinks.consistency_ratio)
0.022
# 示例2: 选择领导
这个例子来源于 WikiPedia (opens new window),人名在代码实现中被修改过,但输入的数据——比较矩阵值,是相同的。
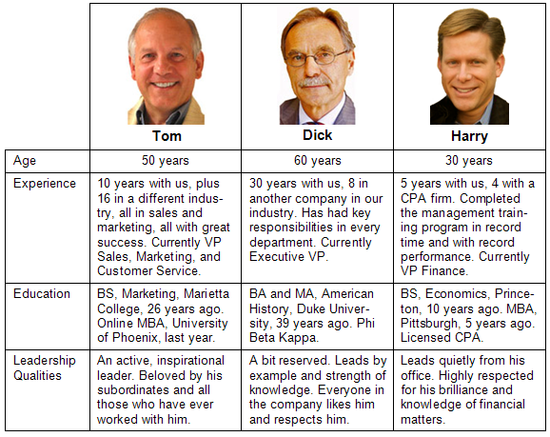
在这个例子中,要根据候选人的经验(Experience)、教育程度(Education)、魅力(Charisma)和年龄(Age)来判断他们。因此,我们需要两两比较潜在的领导者,鉴于每一个评判标准。
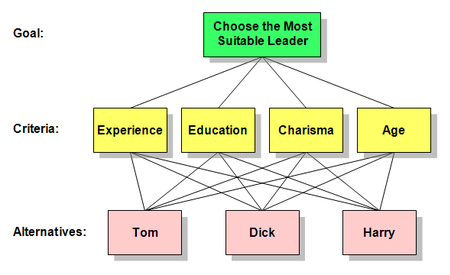
建立评价的层次结构模型如下:
基于 AHPy,它的实现代码如下:
import ahpy
# 总体比较。
# 第一层的两两比较: 经验Experience、教育Education、个人魅力Charisma、年龄Age
criteria_comparisons = {('Experience', 'Education'): 4,
('Experience', 'Charisma'): 3,
('Experience', 'Age'): 7,
('Education', 'Charisma'): 1/3,
('Education', 'Age'): 3,
('Charisma', 'Age'): 5}
# 第二层的比较。
# 注意,人名换了,和上面的图中不同,但使用的数据是一致的。
# 在“经验Experience”上,3个候选人的两两比较:
experience_comparisons = {('Moll', 'Nell'): 1/4,
('Moll', 'Sue'): 4,
('Nell', 'Sue'): 9}
# 在“教育Education”上,3个候选人的两两比较:
education_comparisons = {('Moll', 'Nell'): 3,
('Moll', 'Sue'): 1/5,
('Nell', 'Sue'): 1/7}
# 在“个人魅力Charisma,3个候选人的两两比较:
charisma_comparisons = {('Moll', 'Nell'): 5,
('Moll', 'Sue'): 9,
('Nell', 'Sue'): 4}
# 在“年龄Age”上,3个候选人的两两比较:
age_comparisons = {('Moll', 'Nell'): 1/3,
('Moll', 'Sue'): 5,
('Nell', 'Sue'): 9}
# 开始AHP计算。
experience = ahpy.Compare('Experience', experience_comparisons, precision=3, random_index='saaty')
education = ahpy.Compare('Education', education_comparisons, precision=3, random_index='saaty')
charisma = ahpy.Compare('Charisma', charisma_comparisons, precision=3, random_index='saaty')
age = ahpy.Compare('Age', age_comparisons, precision=3, random_index='saaty')
criteria = ahpy.Compare('Criteria', criteria_comparisons, precision=3, random_index='saaty')
criteria.add_children([experience, education, charisma, age])
# 打印输出结果,最大值为最优选项(选Nell)。
print(criteria.target_weights)
# 输出为:
# {'Nell': 0.493, 'Moll': 0.358, 'Sue': 0.15}
# 示例3: 设定指标权重
某煤矿拟设定一个安全评价指标体系。
该文献以近两年来(2004-2005)国内煤矿安全事故的发生次数和死亡人数,如下表:
| 事故类型 | 次数 | 死亡人数 |
|---|---|---|
| 1. 瓦斯事故(A) | 32 | 891 |
| 2. 水灾事故(B) | 17 | 463 |
| 3. 顶板事故(C) | 22 | 326 |
| 4. 煤尘事故(D) | 9 | 86 |
| 5. 机电运输事故(E) | 11 | 30 |
| 6. 火灾事故(F) | 7 | 30 |
| 7. 放炮事故(G) | 4 | 25 |
建立了煤矿安全现状评价指标体系,并给出比较矩阵:
| 灾害类型 | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| A | 1 | 2 | 3 | 4 | 5 | 6 | 6 |
| B | 1/2 | 1 | 2 | 3 | 4 | 5 | 5 |
| C | 1/3 | 1/2 | 1 | 2 | 3 | 4 | 4 |
| D | 1/4 | 1/3 | 1/2 | 1 | 2 | 3 | 3 |
| E | 1/5 | 1/4 | 1/3 | 1/2 | 1 | 2 | 2 |
| F | 1/6 | 1/5 | 1/4 | 1/3 | 1/2 | 1 | 2 |
| G | 1/6 | 1/5 | 1/4 | 1/3 | 1/2 | 1/2 | 1 |
按层次单排序,计算得到权重值。
| 灾害类型 | 层次单排序 | 归一化 |
|---|---|---|
| A | 3.306395651 | 0.35 |
| B | 2.258782763 | 0.24 |
| C | 1.485994289 | 0.16 |
| D | 0.95973561 | 0.10 |
| E | 0.615152336 | 0.07 |
| F | 0.431334234 | 0.05 |
| G | 0.353838722 | 0.04 |
最终将以归一化的值,可作为每一子项的权重值。
注: 多层次的评价指标体系,可以再次套用上述计算方法。我们把权重理解成为子目标的占比,因此,总体的权重,可以按路径上的子目标的权重乘积得到。
# 小结
层次分析法,是建立层次模型,将领域专家不精确的两两比较,用数学方法拟合出一个“相对靠谱”的权重。它是一种多目标综合评价方法。